Who am I and what is this doc?
I have worked in the data space to some extent for my entire career. My technical skills are largely self-taught. I’ve worked in analytics, data engineering, and architecture, and have implemented data systems across multiple industries and scales. I’ve taught or helped people learn these skills who range from college grads to retirees, and from no programming experience to PHD statisticians.
There are a variety of jobs available in the data space, and they require a wildly different array of skills. Similarly, there’s an intimidatingly large ecosystem of methods and resources to learn these skills. I frequently get asked for assistance in navigating the vast array of resources available to learn these skills. This doc provides an overview of the skills, tools, and courses that I believe are relevant to succeeding as a data professional.
There are many paths to a successful career in data, so this is by no means the “right way”. Nothing here is required and it’s highly opinionated.
Career Progression
Formal Education vs Self Taught
The first formal learning path vs pursuing self taught circulum. Ultimately this decision will depend on your goals and your learning style. However, it’s not an all or nothing decision, and there is a spectrum of options available.
Potentially the most important reason to choose a formal program is your learning style. Some people learn better with the deadlines and accountability of structured circulum. If you want to make a career shift it may be helpful to have a certificate or degree when applying for jobs.
There are a plethora of good courses, bootcamps, and degrees in different aspects of the data world. Regardless of which path you take, you will ultimately get out of these programs what you put into them. Start small with something manageable and free, then move on to paid resources if you are keeping up with the work and enjoying it.
I am a big fan of the Udemy courses below. They’re paid courses, but they are almost always on sale for less than $30 each and they’re well worth that price. I think they strike a good balance between being easy to consume and thorough. Jose Portilla is my favorite data teacher. I wouldn’t be where I am today without his courses. All of the courses below are his except the last one.
- The Complete SQL Bootcamp 2021
- Python for Data Science and Machine Learning Bootcamp
- Data Science and Machine Learning Bootcamp with R
- Spark and Python for Big Data with PySpark
- Scala and Spark for Big Data and Machine Learning
- Data Analysis with Pandas and Python
The next step up from the courses Udemy courses above is a bootcamp program. There are many coding bootcamps out there and they vary wildly in quality and price. Many of these programs are relatively young so proceed with caution. My experience is that they often teach a wide variety of technical skills without much focus on the soft skills required to use data effectively. If you can’t deliver value for an organization, it really doesn’t matter how good you are at using the tools. I was a TA in Northwestern’s Data Analytics Bootcamp, and can recommend it program.
The next step up is a degree from a university. Georgia Tech (here and here)and the University of Illinois (here and here) are both top schools that offer affordable options for online Master’s degrees. I haven’t enrolled in either of these degrees personally, but I know multiple people who have and none of them regret it.
Another noteable resource if you want to go the self taught route is O’Reilly Publishing. Their textbooks are great and they have a book for every topic under the sun when it comes to computer science. Some options I can recommend include Designing Data-Intensive Applications, Spark: The Definitive Guide, Learning Spark, and High Performance Spark. I’m also a big fan of Probabilistic Data Structures and Algorithms for Big Data Applications by Andrii Gakhov.
The Importance of Effective Communication
Communication may be the most important skill that a data professional has to learn. No matter how good of a coder you are, or how good your model is, you’re only as useful as your ability to drive value for your organization.
This can be broken into two broad categories
- Documenting your work. If your work can’t be understood by others it isn’t very useful.
- Selling your work. Every job is a sales job whether you’re selling your companies products or selling your own work internally. Demonstrating the value you provide is paramount to success.
Both are required to be an effective data professional.
An incomplete list of skills senior engineers need, beyond coding
Technical Writing - Documenting Your Work
The models, pipelines, and analyses created by data professional are only as effective as our ability to communicate and document them to our stakeholders and teammates. A less complex output that’s well documented/communicated will always be more effective than a highly advanced or accurate output that no one understands.
Being able to build good documentation for your work is tablestakes when it comes to working with data.
Google’s Technical Writing course is a great place to start when establishing a baseline level of technical communication skills. Also check out the Microsoft Style Guide.
Data Storytelling & Visualizatoin - Selling Your Work
While both are forms of effective communication, technical writing is not the same as data stroytelling. Technical writing is your ability to explain the work you did to make it reproducible while data storytelling refers to our ability to sell our work and influence outcomes. The line between them will occasionally blur, but they are uniquely different skills.
Often this means you need to sell the results of your work internally or externally, or drive a specific outcome. You’re ability to concisely get your point across will be paramount to driving your interests with the right data story.
I included data visualization in this section because the right visual is a huge factor in your ability to communicate effectively. A bar chart that goes up and to the right is almost always more effective than something with more than 2 axes.
If you torture the data long enough, it will confess to anything.
Technical Skills
A Note on Tool Agnosticism
Effective Troubleshooting
More important than any other technical skill set is the ability to research and troubleshoot effectively. This skill will enhance all other technical skill sets.
While the Effective Troubleshooting chapter of Google’s SRE book was written specifically for SREs, the broader concepts outline a troubleshooting framework/mentality that applies to all technical roles. I have yet to find a more generic resource that is as good as this one.
The Command Line + Git
Git and the command line are foundational to every field of programming. They often aren’t taught explicitly, but learning them early will pay dividends throughout your career.
The comand line (and text editor) is the entry point to every programming language. The ability to confidently navigate the terminal will save you countless hours of misguided troubleshooting. The Linux Journey is a great resource to get started with Terminal/Linux. It is easy to follow and broad enough to cover 95% of your use cases.
Along those lines, git is extremely powerful. It is the defacto tool for version control and provides a baseline collaboration model. Learn Git Branching is the best Git tutorial I’ve found so far. It’s interactive so you see the results of every command you run relative to the goal for the problem.
For a more robust guide on DevOps, this git repo has a great walkthrough.
Python vs R
You’ll frequently hear the debate about Python vs R in the data world, and it may seem daunting to make the decision. Python is a general purpose programming language whereas R is a statistical programming language. So while R may be better suited for some of the frequent tasks when working with data, Python has a much wider breadth and can be used for pretty much anything.
When I was first starting out I wanted to go deep on one language that I could apply to a vast array of problems. So I chose Python and never really looked back. For whatever reason, the community has largely aligned behind Python as well. Python is now one of the mostly popular programming languages, largely due to adoption in the data world.
That’s not to say R is a bad language. It may not be as popular overall, but it’s very popular among statisticians and in academia. The R community is very passionate. People who like R really love R.
Jose Portilla’s Python and ML bootcamp is a great place to start when you want to learn python and get started in data science. He has an equivalent course for R, which I haven’t taken.
SQL, Spark, and Pandas
Holistically, learning multiple tools to work with data. Excel, SQL, Python, and Spark are all tools you can use to work with data. They all have comparable operations to work with data and they’re all suited for different situations.
Learning multiple tools and being able to separate the operation you need to perform from the tool you’re using will make you a better data professional. It will be easier to troubleshoot, to learn new tools, and to build effective solutions as you progress through your career.
If your only tool is a hammer, then every problem looks like a nail.
SQL
SQL is a fundamental tool for any data professional. It’s largely unavoidable whether you’re a data scientist, engineer, or analyst. You can build an entire career in data knowing some SQL, PowerPoint, and Excel.
SQL Interview Questions
You’ll be way ahead of most SQL analysts If you have a solid grasp on execution query execution order, joins, window functions, and where vs having clauses. If you can also perform them confidently in Pandas and Spark on top of SQL, you’ll be on another level.
SQL Quick Reference
SQL (Structured Query Language) is used for querying, manipulating, defining, and controlling access to data in relational database management systems. There are several flavors of SQL created by different organizations, but most operate on the same basic principles with slightly different syntax.
Select… From… Where…
SELECT - these columns
FROM - this table
WHERE - these criteria are met
Almost every query that extracts data from a database will have these three clauses in order to specify which data you need. They’re always used in the same order.
For example:
Table:
| Year | Person | Income |
|---|---|---|
| 2016 | James | 10,000 |
| 2016 | Kate | 11,000 |
| 2016 | Sam | 10,000 |
| 2017 | James | 10,000 |
| 2017 | Kate | 12,000 |
| 2017 | Sam | 11,000 |
| 2018 | James | 11,000 |
| 2018 | Kate | 12,000 |
| 2018 | Sam | 12,000 |
Query:
SELECT year, person
FROM income_table
WHERE income > 11,000Results:
| Year | Person |
|---|---|
| 2017 | Kate |
| 2018 | Kate |
| 2018 | Sam |
In other words, the output of the query is the intersect of the SELECT and WHERE clauses.
Dimensions vs Metrics
Dimensions are attributes of our data, they are not aggregated. Meanwhile metrics are quantitative measurements that are aggregated.
The GROUP BY clause is added to the end of a query that contains aggregation functions in order to distinguish between the dimensions and metrics in the query.
SELECT person
, COUNT(DISTINCT year) AS years
, SUM(income) AS money_earned
FROM income_table
WHERE year > 2016
AND income > 10,000
GROUP BY person| person | years | money_earned |
|---|---|---|
| Kate | 3 | 35,000 |
| Sam | 2 | 23,000 |
| James | 1 | 11,000 |
Aggregation Functions
Aggregation functions create metrics by performing a quantitative operation on a column.
COUNT()/SUM()/AVG()/MAX()/MIN()COUNT(*)- counts the number of rows in the tableCOUNT(DISTINCT <column_name>)- counts the number of unique values in a columnCOUNT(<column_name>)- counts the number of rows in a column where there is a non-NULL value
Additional Useful Syntax
IN - enables the specification of multiple values to satisfy a criterion in a WHERE clause.
LIMIT XX - limits the number of rows returned by a query to the first XX number of rows in the result set.
ORDER BY <column_name> ASC|DESC - sorts the output by one or more of the columns in the resulting table (defaults to ASC)
SQL Joins
Joins are used to pull data from multiple tables into one, combined, output. They match rows from the tables based on one or more related columns, or keys.
It’s important to consider which type of join correctly represents the data you’re trying to pull. Incorrectly joining data can result in the wrong data being pulled.
A VLOOKUP is the equivalent of a LEFT JOIN in Excel.
Note:
LEFT JOIN=LEFT OUTER JOINRIGHT JOIN=RIGHT OUTER JOININNER JOIN=JOIN
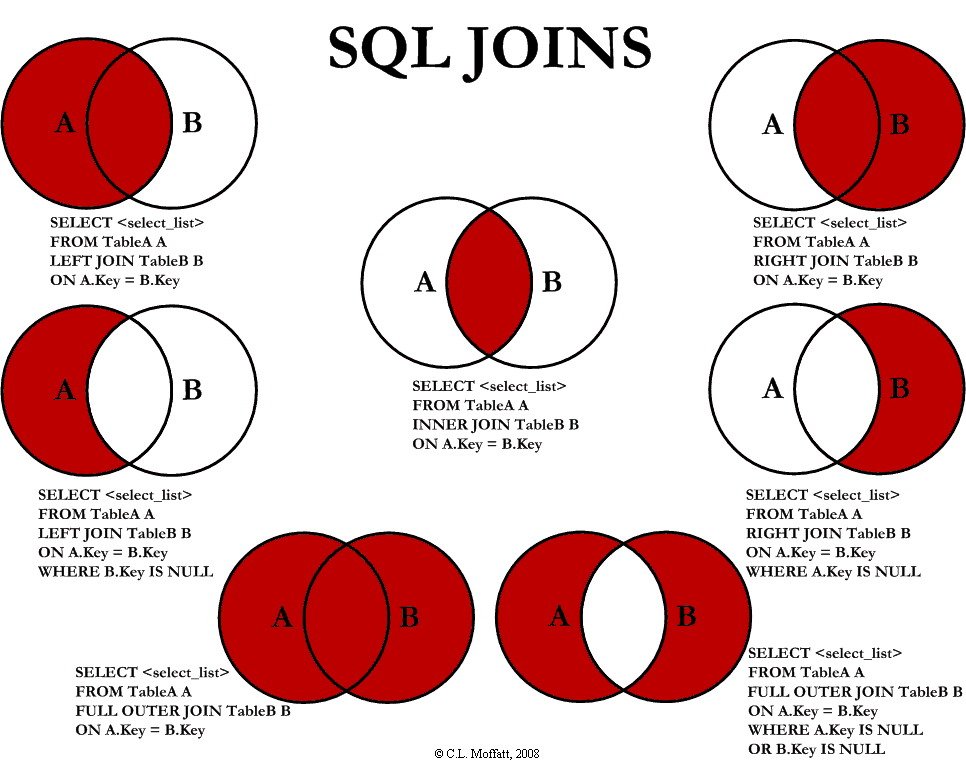
Aliases
When you’re only using one table and you call on a column, it’s understood what table the field is coming from. However, when you’re calling on multiple tables in one query (as is the case when you’re joining two tables), aliases are used so you don’t have to use a table’s full name every time you call on it or a column it contains.
Pandas
Pandas is the standard Python library for data analysis. Think of it as “Excel for Python”. You can get pretty far in your career only knowing Pandas. As long as your data is small enough to keep your work confined to a single machine, Pandas should do the trick. Boris Paskhaver’s course on Pandas (referenced above) is an pretty thorough resource covering Pandas.
Spark
While Pandas has come to rule the world of single machine data processing in Python, Spark dominates the industry of Big Data processing engines. Jose Portilla’s courses for Spark (linked above) in both Scala and Python cover a lot of the same content as the Python for DS and ML bootcamp, but he talks about how do those things in Spark rather than single machine Python.
If you’re just starting out, I would recommend focusing on Python rather than Scala. Python is much easier to learn and for the most part you’ll benefit in the beginning from consolidating on one programming language and going deep on that language.
IDEs
Jupyter
Jupyter is often the first IDE that’s taught in data courses. It offers an interactive notebook environment that allows for fast prototyping. As a whole the data community likes notebooks a lot because of the ease of iteration and the ability to display Markdown, Latex, and visualizations in the notebook alongside code. This makes them a good medium to communicate projects and results to other technical stakeholders.
Jupyter is the most popular in the Python world. However, Jupyter is short for Julia Python R, and there are available kernels for several other languages.
However, notebooks can be a terror to productionize. Inexperienced data scientists frequently run notebook cells out of order which harms reproducibility by causing state issues.
Databricks
Disclaimer: I work for Databricks.
Databricks was founded by the creators of Apache Spark. They offer a managed notebook environment and Spark clusters via a cloud-hosted SaaS product for data analytics, data science, and data engineering.
Troubleshooting Python environments is notoriously difficult for beginners (relevant XKCD). Using Databricks, or a similar offering, eliminates most of these issues. Additionally because Databricks created Spark, it will always be the best place to run Spark workloads.
They offer a version of their software for free called Databricks Community Edition. While limited, it’s more than enough for anyone just starting out in the data space. Overall, Databricks Community Edition is a happy medium between being powerful enough to have what you need, but not being overwhelming when you’re starting out.
Visual Studio Code
Visual Studio Code (or VS Code) is Microsoft’s light weight, open source text editor. It is my favorite text editor because it’s robust enough to do everything I need while still not being as heavy as a full blown IDE like PyCharm or Visual Studio. For anything that it can’t do out of the box, there is a robust ecosystem of extensions to fill the gap.
PyCharm
PyCharm gets an honorable mention here because it is an industry favorite. The JetBrains IDEs in general, are favorites across most languages. I’ve never run into a situation where the benefits of the IDE outweighed the costs. The learning curve is steep and it’s a heavy piece of software.
One time I complained to my coworker about how long PyCharm takes to launch and he said he leaves it open all the time. I joked that his method had the dual benefit of saving money on his energy bill because he could heat his apartment off his laptop.